Filtratieprobleem aanpakken
met Data Science
De situatie:
In fabriek A wordt batchgewijs een (tussen)product gemaakt. In fabriek B wordt batchgewijs, via een aantal bewerkingsstappen, het tussenproduct omgezet tot een commercieel eindproduct.
In één van de bewerkingsstappen in fabriek B, wordt een waterige suspensie van het tussenproduct via een filter overgepompt van tank 1 naar tank 2. Fabrieken A en B, hoewel fysiek behoorlijk van elkaar gescheiden, zijn beide eigendom van hetzelfde bedrijf.
Het probleem:
De filtratiestap geeft bij een behoorlijk aantal batches per jaar problemen, zonder dat duidelijk is of dat ontstaat door de instellingen (enigszins operator afhankelijk), de wegwerpfilters zelf, of de kwaliteitseigenschappen van het tussenproduct. De problemen uiten zich in lange filtratietijden (tot drie maal langer dan normaal) en in extra filterwissels die tot productverlies leiden. De filtratietijden worden niet formeel in sap geregistreerd, waardoor de omvang van de problematiek niet goed duidelijk is.
De vraag:
Waar liggen de mogelijke oorzaken van de filtratieproblemen, zodat die aangepakt kunnen worden? En ook van belang: wat zijn juist geen mogelijke oorzaken, zodat daaraan geen tijd hoeft te worden gespendeerd?
"Hoewel de ruwe data uit ERP systemen als SAP en LIMS door bedrijven vaak ervaren worden als lastig toegankelijk, is de verwerking daarvan tot analyseerbare datasets voor Data Science software redelijk eenvoudig"
De aanpak:
De productieschaal, de kosten en ook andere omstandigheden, maken het doen van experimenten feitelijk onmogelijk. Daarom is besloten te onderzoeken of met hulp van Data Science, beschikbare ERP en sensordata omgezet kunnen worden naar aanwijzingen voor oorzaken van de filtratieproblemen.
De ERP/SAP/LIMS data van het productieproces van beide fabrieken (A en B), over de afgelopen twee jaar, werden uit SAP en LIMS geëxporteerd. Die data bevat gegevens over welke batches wanneer werden geproduceerd, met welke batches grondstoffen, en met welke gemeten kwaliteitseigenschappen aan tussen- en eindproducten. Hetzelfde werd gedaan voor de SCADA systemen van fabriek B. Die data bevat lange series sensordata in de fabriek, zoals sensoren in de apparatuur, die een aantal maal per minuut zaken meten als temperaturen, drukken of gewichten. Op die manier werd de data beschikbaar gesteld voor de Data Science software.
"Wel worden ERP data nogal eens afgeschilderd als 'bevat veel fouten'. Maar de software kan helpen daar slim mee om te gaan, en veel laten leren uit de goede ERP data"
Hoewel de ruwe data uit ERP systemen als SAP en LIMS door bedrijven vaak ervaren worden als lastig toegankelijk, is de verwerking daarvan tot analyseerbare datasets voor Data Science software redelijk eenvoudig. Ook als dat grote meerjarige datasets betreft. Mits natuurlijk de data via batch- of ordernummers aan elkaar gekoppeld kunnen worden. Dat moet goed gecontroleerd worden, maar is in ERP systemen vaak goed geregeld. Wel worden ERP data nogal eens afgeschilderd als “bevat veel fouten”. Maar de software kan helpen daar slim mee om te gaan, en veel laten leren uit de goede ERP data.
Lastiger is het verwerken van de sensordata uit systemen als SCADA of MES. De ruwe data zelf is vaak nog goed toegankelijk, hoewel heel volumineus met miljoenen datarijen per sensor. Maar die ruwe informatie omzetten naar zinvolle datasets voor analyse, vergt een samenwerking tussen procesengineers, die weten hoe de proceslogica in elkaar steekt, en de meer data science gerichte engineers, die begrijpen welke datastructuren zinvol zijn bij de gewenste soort analyse. Die omzetting vergt wat tijd, maar is cruciaal. Bovendien vergt het competentie-ontwikkeling in uw team van engineers, iets wat kan groeien over de jaren. Ook hier is het belangrijk dat de ERP informatie over batchnummers gekoppeld is met datum/tijd momenten in de verschillende stappen van het productieproces. Deze koppeling is niet altijd volledig voor handen, maar kan met de Data Science software vaak wel goed worden gereconstrueerd. Gelukkig maar, want zonder een goede koppeling van batchnummers naar productiemomenten is verdere analyse niet mogelijk.
"De oorspronkelijke dataset bevat enkele honderden parameters die beschikbaar zijn voor analyse"
De resultaten:
De data in dit voorbeeld zijn geïnspireerd op oorspronkelijke data, maar zodanig geanonimiseerd dat alleen de grove conclusies overeind blijven. In onderstaand plaatje wordt de duur van de filtratie zichtbaar gemaakt met de oranje lijn. Die toont hoe een tank via een filter geleegd wordt, via de sensorwaarde van het gewicht in de tank. De tank bevat één batch materiaal.
Tekst gaat verder onder de afbeelding
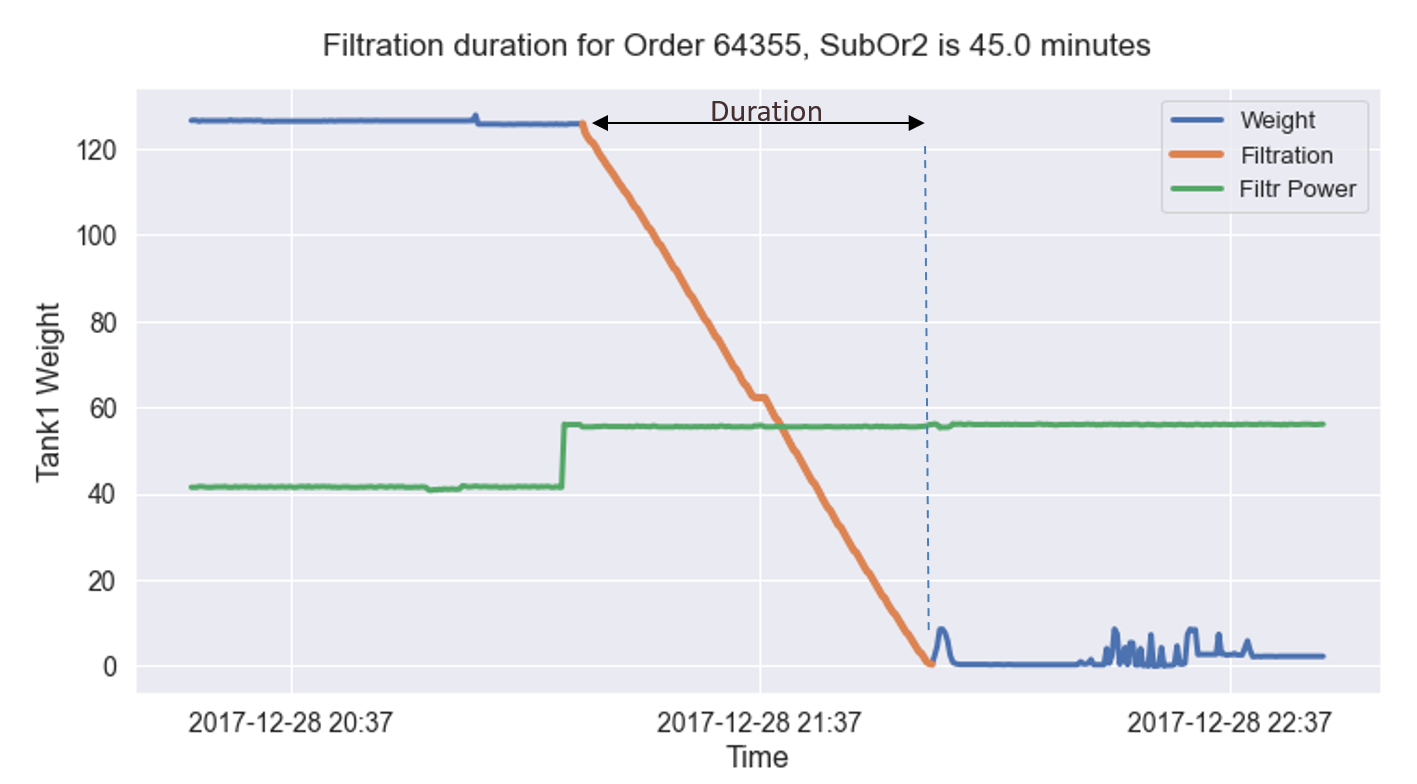
De software voert deze berekening uit op de sensordata voor alle batches, en dat levert onderstaand plaatje op. Daarin staat de filtratietijd op de verticale as, en de batchnummers chronologisch op de x-as over een langere periode.
Tekst gaat verder onder de afbeelding
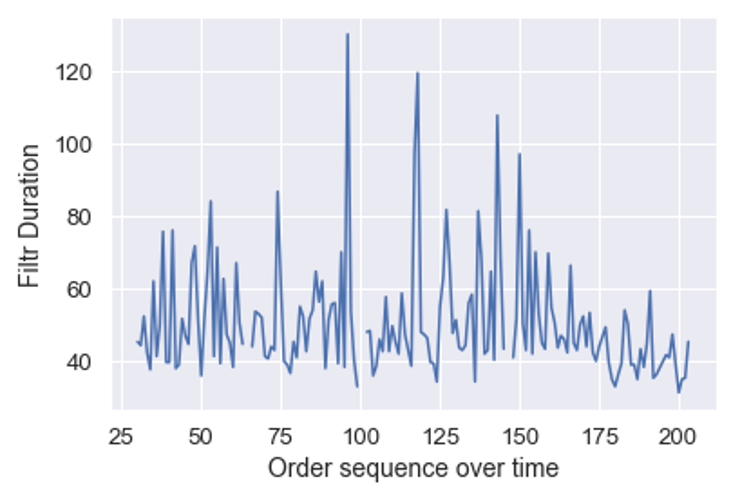
Hieruit blijkt dat de filtratietijd inderdaad behoorlijk variabel is, hoewel er ook periodes zijn met minder variabiliteit. Hoewel een procesengineer uit het patroon wellicht al ideeën kan krijgen, is er nog geen relatie met mogelijke oorzaken.
De oorspronkelijke dataset bevat enkele honderden parameters die beschikbaar zijn voor analyse. Hieronder worden ter illustratie drie correlatiegrafieken getoond. De filtratieduur is de verticale as.
Tekst gaat verder onder de afbeelding
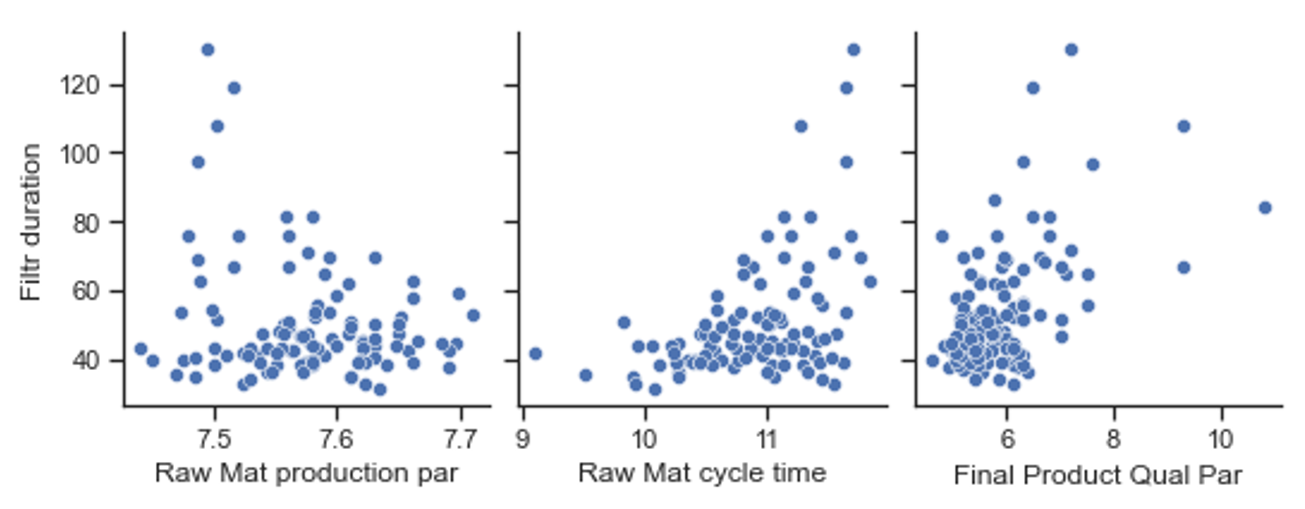
Het rechter plaatje toont op de x-as een kwaliteitsparameter van het eindproduct van fabriek B (hoe lager die waarde, hoe beter het product). Hieruit is zichtbaar dat de filtratieduur een correlatie heeft met de eindkwaliteit. Hogere filtratieduren correleren met een slechter eindproduct. Hoewel er nog veel productiestappen uitgevoerd worden ná de filtratiestap, is de correlatie toch goed zichtbaar. Of de correlatie oorzakelijk is, wordt met alleen dit plaatje nog niet duidelijk.
Het middelste plaatje toont ook een correlatie, hoewel geen rechte lijn. Op de x-as staat een parameter die een maat is voor de cyclustijd waarmee een batch door fabriek A gegaan is. Dit plaatje koppelt dus iets dat in fabriek B problemen geeft, aan iets dat eerder in fabriek A gebeurd is. Wát in fabriek A de aanleiding is voor dit verband, wordt in het plaatje niet duidelijk. Maar de procesengineers van fabriek A kunnen nu wel gerichter gaan nadenken over parameters die verband houden met de cyclustijd.
Het linker plaatje heeft een x-as die een productieparameter is die in SAP van fabriek A gelogd wordt. De correlatie is zwak, maar het plaatje toont wel aan dat al in deze fase van het proces in fabriek A zaken spelen die veel later in fabriek B problemen veroorzaken.
Tot slot nog een opmerking over wat er níet belangrijk bleek te zijn. Dat waren onder andere de verschillen in filtratie-instellingen tussen sommige operators in fabriek B, en de wegwerpfilters in fabriek B. De correlaties tussen de filtratieduur en de parameters in fabriek A hadden nooit zichtbaar kunnen worden als b.v. de wegwerpfilters de enige oorzaak voor het probleem waren geweest.
"Data Science technieken maken het mogelijk om, zonder het uitvoeren van experimenten, in een “stabiel” commercieel proces, toch richting oorzaken van problemen te komen"
Conclusies:
Data Science technieken maken het mogelijk om, zonder het uitvoeren van experimenten, in een “stabiel” commercieel proces, toch richting oorzaken van problemen te komen. Dat is mogelijk als er een (vrij) grote hoeveelheid data voor analyse beschikbaar is. Op deze manier kan een scheiding gemaakt worden van zeer veel mogelijke oorzaken in twee fabrieken, naar kleine gebieden in die fabrieken, waar de oorzaken gevonden zullen moeten kunnen worden.
Tot slot:
Procesengineers hebben historisch gezien veel problemen opgelost door naar het fysieke proces te kijken, met beperkte hoeveelheden data en experimenten. In de nabije toekomst zullen procesengineers ook specialiseren in het digitale proces, om daarmee meer, sneller en goedkoper procesproblemen op te lossen. Dat is minder lastig dan het in eerste instantie lijkt, maar vergt wel interesse in de groei in moderne Data Science technieken.
"In de nabije toekomst zullen procesengineers ook specialiseren in het digitale proces"
Loopt u tegen soortgelijke problemen aan? Doe dan een beroep op Quality Target en haal meer resultaat uit uw verbeterbudget.
Ook iets voor u?
